
TRUFV2: Now Your Data Flies Like It’s On Caffeine
Data up. Storage down. Speed maxed.

Day 80 of 100 Days of TRUF
You know that feeling when you hit SELECT * FROM reality and it takes just long enough for you to contemplate your life choices? Yeah, we killed that.
With TRUFV2, your queries don’t stroll to the finish line anymore, they sprint. Not because we asked you nicely to optimize your own stack, but because we went ahead and did it for you. Built-in. Always on. No extra config.
This isn’t “oh, it’s 10% faster” marketing fluff. We’re talking orders of magnitude faster, sometimes half the time, sometimes 90% less latency. Whether you’re pulling price feeds, weather indexes, or the next big prediction market signal, it just shows up. No waiting room, no “please hold” music.
Why? Because Caching.
We baked a caching layer right into every TRUF node. Tell it which indexes you want on tap, and they’ll already be sitting there, hot and ready when you call. No repetitive heavy lifting. No “just-in-time” panic pulls. You could run this thing in production at scale without sweating your cloud bill.
And here’s the kicker: nobody else in Web3 data infra is doing this for you out-of-the-box. If you were rolling your own SQL stack, you’d be building this caching yourself. But you’re on TRUF, so you get to skip that part and just… build your product.
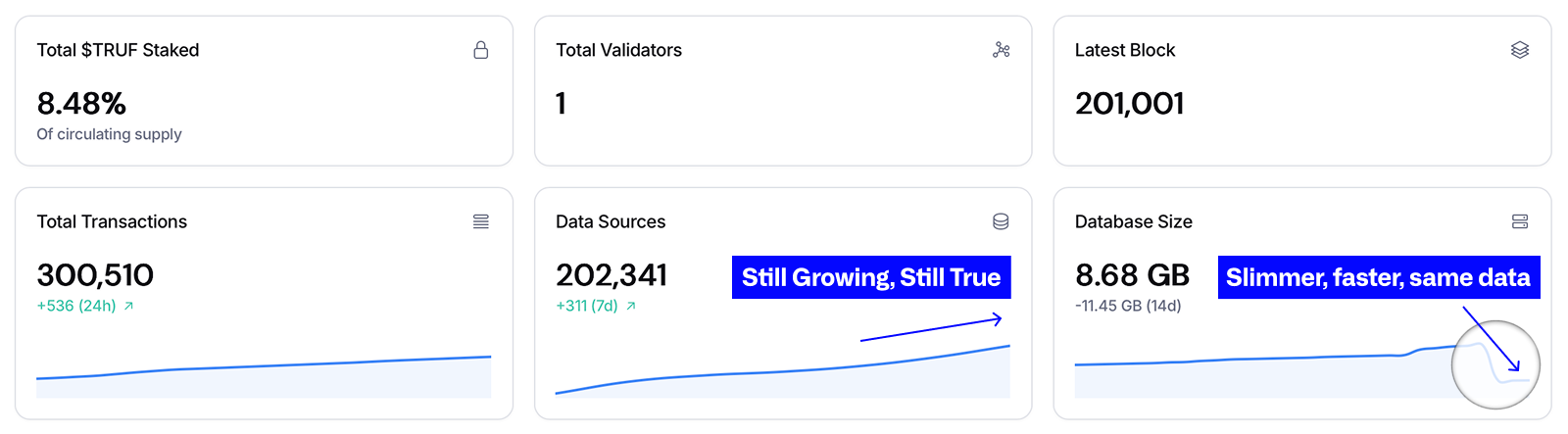
Oh, and the Database Went on a Diet.
Big databases get sluggish. TRUFV2 just rewired its schema so we store the same amount of data in way less space. Think 25 gigs down to 9 gigs without losing a single record. That’s a 65%+ drop in storage size; meaning your node now runs happily on the smallest AWS instance you can rent.
We didn’t throw out your data. Sources and records kept climbing; we just got better at packing them. This is the kind of efficiency upgrade that turns “yeah, we could run a node” into “we can run three and still come in under budget.”
Translation for Developers
- Faster queries without extra code.
- Cheaper nodes without cutting data.
- You can run lean, scale big, and still deliver millisecond-level performance for high-frequency, high-volume retrieval.
This is a baseline speed and efficiency boost for every app, service, or prediction market built on top, not simply a network upgrade. If your project needs a real-time source of truth, you can’t afford to run on old infrastructure.
The migration’s done. TRUFV1 is dead. Every critical node is now TRUFV2. You can spin up in minutes, connect, and start moving real-world data at real-world speed today.